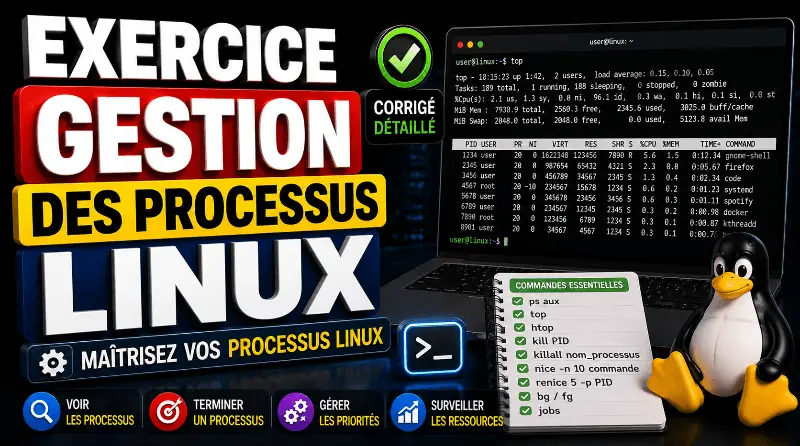
Les exercices pratiques sur la gestion des processus linux comportent des exercices théoriques et pratiques sur les concepts fondamentaux de la gestion des processus, y compris la création, la planification, et la terminaison des processus. Vous aurez l’occasion d’explorer des commandes essentiels tels que ps et top pour surveiller les processus en temps réel, ainsi que d’utiliser des commandes comme kill pour gérer les processus.
De plus, des exercices aborderont la gestion de la mémoire, l’utilisation des identifiants de processus (PID), ainsi que l’interaction entre les processus via des signaux. Les travaux pratiques incluront des scénarios de simulation où vous pouvez créerer des scripts pour automatiser la gestion des processus et résoudre des problèmes courants liés aux processus orphelins et aux zombies.
L’objectif est de fournir une compréhension approfondie de la manière dont le système d’exploitation Linux gère les processus, ainsi que des compétences pratiques pour gérer efficacement les processus dans un environnement réel.
Exercice 1: Question générale sur la gestion des processus Linux
1.1) Considérons l’exemple de code suivant provenant d’un simple programme shell.
Supposons maintenant que l’interpréteur de commandes souhaite rediriger la sortie de la commande vers un fichier « file.txt » et non vers STDOUT. Montrez comment vous modifieriez le code ci-dessus pour réaliser cette redirection de sortie. Vous pouvez indiquer vos modifications à côté du code ci-dessus.
Voici comment vous pouvez modifier le code pour rediriger la sortie vers file.txt en utilisant close et open:
Comme exec échoue, le code suivant dans l’enfant s’exécute.
La ligne printf("child\n"); sera exécutée.
Processus parent (ret > 0) :
Appelle wait(), attendant que l’enfant se termine.
Une fois l’enfant terminé, il exécute printf("parent\n");.
1.3) Considérons l’extrait de code suivant, dans lequel un processus parent fork un processus enfant. L’enfant exécute une tâche pendant sa durée de vie, tandis que le processus parent exécute deux tâches différentes.
int ret = fork();
if(ret == 0) { do_child_task(); }
else {
do_parent_task1();
do_parent_task2();
}
De la manière dont le code est écrit actuellement, l’utilisateur n’a aucun contrôle sur l’ordre dans lequel les tâches parent et enfant s’exécutent, car l’ordonnancement des processus est effectué par le système d’exploitation. Ci-dessous sont présentés deux ordres possibles des tâches que l’utilisateur souhaite imposer. Pour chaque partie, décrivez brièvement comment vous modifierez le code donné ci-dessus pour garantir l’ordre des tâches requis. Vous pouvez rédiger votre réponse en français ou en pseudo-code.
Notez que vous ne pouvez en aucun cas modifier le mécanisme d’ordonnancement du système d’exploitation pour résoudre cette question. Si un processus est programmé par le système d’exploitation avant que vous ne souhaitiez que sa tâche soit exécutée, vous devez utiliser des mécanismes tels que les appels système et les techniques IPC disponibles dans l’espace utilisateur pour retarder l’exécution de la tâche jusqu’à un moment approprié.
(a) Nous voulons que le processus parent commence l’exécution de ses deux tâches seulement après que le processus enfant ait terminé sa tâche et se soit arrêté.
(b) Nous voulons que le processus enfant exécute sa tâche après que le processus parent ait terminé sa première tâche, mais avant qu’il n’exécute sa deuxième tâche. Le processus parent ne doit pas exécuter sa deuxième tâche tant que le processus enfant n’a pas terminé la sienne et ne s’est pas arrêté.
(a) Parent attend que l’enfant termine avant de commencer ses tâches
Pour garantir que le processus parent commence l’exécution de ses deux tâches seulement après que le processus enfant ait terminé, vous pouvez utiliser wait(). Voici le code modifié:
int ret = fork();
if (ret == 0) {
do_child_task(); // Tâche de l'enfant
} else {
wait(NULL); // Le parent attend que l'enfant se termine
do_parent_task1(); // Tâche 1 du parent
do_parent_task2(); // Tâche 2 du parent
}
(b) Parent exécute la première tâche avant l’enfant, puis attend la fin de l’enfant
Pour que le processus parent exécute sa première tâche avant que l’enfant ne commence et n’exécute sa deuxième tâche qu’après que l’enfant ait terminé, vous pouvez utiliser des tubes (pipes) pour synchroniser les processus. Voici un exemple de code modifié:
int pipe1[2], pipe2[2];
pipe(pipe1); // Tube pour synchroniser le parent vers l'enfant
pipe(pipe2); // Tube pour synchroniser l'enfant vers le parent
int ret = fork();
if (ret == 0) {
close(pipe1[1]); // Ferme l'extrémité d'écriture du tube 1
read(pipe1[0], NULL, 0); // L'enfant attend un signal du parent
do_child_task(); // Tâche de l'enfant
close(pipe2[0]); // Ferme l'extrémité de lecture du tube 2
write(pipe2[1], NULL, 0); // Signale au parent que l'enfant a fini
} else {
do_parent_task1(); // Tâche 1 du parent
close(pipe1[0]); // Ferme l'extrémité de lecture du tube 1
write(pipe1[1], NULL, 0); // Signale à l'enfant de commencer
close(pipe2[1]); // Ferme l'extrémité d'écriture du tube 2
read(pipe2[0], NULL, 0); // Le parent attend que l'enfant termine
do_parent_task2(); // Tâche 2 du parent
}
Résumé:
(a) Utiliser wait() pour que le parent attende l’enfant.
(b) Utiliser des tubes pour synchroniser les tâches entre le parent et l’enfant.
1.4) Quelles sont les sorties possibles affichées à partir de ce programme illustré ci-dessous ? Vous pouvez supposer que le programme s’exécute sur un système d’exploitation moderne de type Linux. Vous pouvez ignorer toute sortie générée à partir de « quelque_executable ». Vous devez prendre en compte tous les scénarios possibles de réussite ou d’échec des appels système. Dans votre réponse, énumérez clairement tous les scénarios possibles et la sortie du programme dans chacun de ces scénarios.
Voici les sorties possibles pour le programme donné, en tenant compte des différents scénarios d’exécution:
Cas I: fork et exec réussissent Sortie:
Hello1
Hello3
Explication: Le processus enfant affiche « Hello1 » puis exécute quelque_executable. Comme exec réussit, la ligne suivante (printf(« Hello2\n »);) n’est pas exécutée. Le parent attend que l’enfant se termine avant d’afficher « Hello3 ».
Cas II: fork réussit mais exec échoue Sortie:
Hello1
Hello2
Hello3
Explication: Le processus enfant affiche « Hello1 » mais échoue lors de l’exécution de exec. Il continue donc à exécuter la ligne suivante et affiche « Hello2 ». Ensuite, le parent attend que l’enfant se termine (qui se termine après avoir affiché « Hello2 ») avant d’afficher « Hello3 ».
Cas III: fork échoue Sortie:
Hello4
Explication: Si fork échoue, le code du parent ne sera pas exécuté, mais le else s’exécute et affiche « Hello4 ». Aucune autre sortie n’est générée.
1.5) Considérez l’exemple de code suivant issu d’un programme shell simple.
(a) Dans le code ci-dessus, les deux commandes cmd1 et cmd2 s’exécutent-elles en série (l’une après l’autre) ou en parallèle ?
(b) Indiquez comment vous modifieriez le code ci-dessus pour changer le mode d’exécution de série à parallèle ou vice versa. Autrement dit, si vous avez répondu « série » dans la partie (a), vous devez modifier le code pour exécuter les commandes en parallèle, et vice versa. Indiquez vos modifications à côté de l’extrait de code ci-dessus.
(a) Réponse: Les deux commandes cmd1 et cmd2 s’exécutent en parallèle. Le processus parent crée un enfant pour cmd1, puis crée un deuxième enfant pour cmd2, et les deux enfants s’exécutent simultanément.
(b) Modifier le code pour l’exécution en série. Pour changer l’exécution des commandes de parallèle à série, il faut que le processus parent attende la fin de cmd1 avant de lancer cmd2. Voici comment modifier le code:
int rc1 = fork();
if (rc1 == 0) {
exec(cmd1);
} else {
wait(); // Attendre que cmd1 se termine
int rc2 = fork();
if (rc2 == 0) {
exec(cmd2);
} else {
wait(); // Attendre que cmd2 se termine
}
}
Modifications: Déplacer la première wait() avant le deuxième fork(): Cela garantit que le parent attend que cmd1 se termine avant de créer un processus pour cmd2.
1.6) Considérons l’extrait de code suivant, qui s’exécute sur un système d’exploitation Linux moderne (avec une politique d’ordonnancement préemptive raisonnable). Supposons qu’il n’y ait pas d’autres processus interférents dans le système. Notez que l’exécutable « good_executable » s’exécute pendant 100 secondes, affiche la ligne « Hello from good_executable » à l’écran et se termine. En revanche, le fichier « bad_executable » n’existe pas et entraînera l’échec de l’appel système exec.
int ret1 = fork();
if(ret1 == 0) { //Child 1
printf("L'enfant 1 a démarré\n");
exec("good_long_executable");
printf("L'enfant 1 a terminé\n");
}
else { //Parent
int ret2 == fork();
if(ret2 == 0) { //Child 2
//La mise en sommeil permet à l'enfant 1 de commencer l'exécution
sleep(10);
printf("L'enfant 2 a démarré\n");
exec("bad_executable");
printf("L'enfant 2 a terminé\n");
} //end of Child 2
else { //Parent
wait();
printf("Enfant récupéré\n");
wait();
printf("Parent terminé\n");
}
}
Écrivez la sortie du programme ci-dessus.
Sortie:
L'enfant 1 a démarré
L'enfant 2 a démarré
(Un message d'erreur provenant du mauvais exécutable)
L'enfant 2 a terminé
Enfant récupéré
Hello from good_executable
Parent terminé
Explication des sorties:
« L’enfant 1 a démarré » – affiché par Child 1 immédiatement après le fork().
« L’enfant 2 a démarré » – affiché par Child 2 après la période de sommeil de 10 secondes.
« (Un message d’erreur provenant du mauvais exécutable) » – généré lorsque Child 2 essaie d’exécuter bad_executable, qui n’existe pas, entraînant une erreur d’exécution.
« L’enfant 2 a terminé » – affiché après que Child 2 se termine à cause de l’échec de exec.
« Enfant récupéré » – affiché par le parent après avoir récupéré Child 2.
« Hello from good_executable » – affiché par good_executable pendant son exécution, mais il apparaîtra après « Enfant récupéré ».
« Parent terminé » – affiché par le parent après que tous les enfants ont été récupérés.
1.7) Quelle est la sortie affichée par l’extrait de pseudocode suivant ? Si vous pensez qu’il y a plus d’une réponse possible en fonction de l’ordre d’exécution des processus, vous devez énumérer toutes les sorties possibles.
Ces sorties montrent comment l’ordonnancement des processus peut influencer le comportement du programme.
1.8) Quel est le résultat du programme suivant? Seuls les extraits de code pertinents sont montrés, et vous pouvez supposer que le code se compile et s’exécute correctement.
int a = 2;
while(a > 0) {
int ret = fork();
if(ret == 0) {
a++;
printf("a=%d\n", a);
}
else {
wait(NULL);
a--;
}
}
Le code entre dans une boucle while+fork infinie, car chaque processus enfant qui est forké exécutera le même code avec une valeur plus élevée de « a » et donc la boucle while ne se termine jamais. Il y aura un nombre infini de processus enfants qui afficheront a=3,4,5, et ainsi de suite, jusqu’à ce que la fork échoue ou que le système utilise une autre ressource.
Comportement détaillé
Boucle infinie :
Chaque fois qu’un processus enfant est forké, il incrémente a (qui commence à 2) avant d’afficher sa valeur.
Les enfants successifs augmentent a de 1 à chaque fork, entraînant des valeurs de a = 3, 4, 5, etc.
Processus parent :
Pendant ce temps, le parent décrémente a après avoir attendu la fin de l’enfant, mais à chaque itération, de nouveaux enfants continuent à être créés et à augmenter a.
Résultat :
La boucle continue indéfiniment, avec une production continue d’enfants qui affichent des valeurs de a croissantes.
La sortie affichera des lignes comme:
a=3
a=4
a=5
...
Cela continuera jusqu’à ce qu’une limite système soit atteinte (comme la limite du nombre de processus) ou que le système rencontre une erreur.
1.9) Quel est le résultat du programme suivant ? Seuls les extraits de code pertinents sont montrés, et vous pouvez supposer que le code se compile et s’exécute correctement.
int a = 2;
while(a > 0) {
int ret = fork();
if(ret == 0) {
a++;
printf("a=%d\n", a);
execl("/bin/ls", "/bin/ls", NULL);
}
else {
wait(NULL);
a--;
}
}
Résumé du Programme
Initialisation:
int a = 2;: La variable a commence à 2.
Boucle while :
Tant que a > 0, le programme fork un enfant.
Processus Enfant (ret == 0) :
Incrémente a (devient 3).
Affiche a=3.
Exécute execl("/bin/ls"), remplaçant l’enfant par la commande ls.
Processus Parent (ret > 0) :
Attend que l’enfant se termine.
Décrémente a (devient 1 après le premier enfant).
Deuxième itération :
Fork un nouvel enfant (qui incrémente a à 2, affiche a=2, et exécute ls).
Sortie:
a=3
<sortie de la commande ls>
a=2
<sortie de la commande ls>
Chaque enfant affiche sa valeur avant d’exécuter ls.
1.10) Considérez une application composée d’un processus master et de plusieurs processus worker qui sont forkés à partir du master au début de l’exécution de l’application. Tous les processus ont accès à un pool de pages de mémoire partagée et ont la permission de lire et d’écrire dans cette mémoire. Cette région de mémoire partagée (également appelée tampon de requêtes) est utilisée comme suit: le processus master reçoit des requêtes entrantes des clients via le réseau et écrit les requêtes dans le tampon de requêtes partagé. Les processus worker doivent lire la requête depuis le tampon de requêtes, la traiter et écrire la réponse dans la même région du tampon. Une fois la réponse générée, le serveur doit répondre au client. Le serveur et les processus worker sont mono-threadés, et le serveur utilise des E/S basées sur des événements pour communiquer avec les clients sur le réseau (vous ne devez pas rendre ces processus multi-threadés). Vous pouvez supposer que la requête et la réponse ont la même taille, et que plusieurs requêtes ou réponses de ce type peuvent être accommodées dans le tampon de requêtes. Vous pouvez également supposer que le traitement de chaque requête prend un temps CPU similaire pour les threads de travail. En utilisant cette idée de conception comme point de départ, décrivez les mécanismes de communication et de synchronisation qui doivent être utilisés entre le serveur et les processus worker, afin de permettre au serveur de déléguer correctement les requêtes et d’obtenir des réponses des processus worker. Votre conception doit garantir que chaque requête placée dans le tampon de requêtes est traitée par un seul et unique thread de travail. Vous devez également veiller à ce que le système soit efficace (par exemple, aucune requête ne doit être maintenue en attente si un worker est libre) et équitable (par exemple, tous les workers partagent la charge presque également). Bien que vous puissiez utiliser n’importe quel mécanisme de IPC de votre choix, assurez-vous que votre conception système est suffisamment pratique pour être mise en œuvre dans un système multicœur moderne fonctionnant sous un système d’exploitation comme Linux. Vous n’avez pas besoin d’écrire de code, et une description claire, concise et précise en anglais devrait suffire.
Communication et Synchronisation entre le Serveur et les Processus Worker
Pour assurer une communication efficace et une synchronisation entre le processus maître (serveur) et les processus workers, nous pouvons utiliser une combinaison de mémoire partagée et de sémaphores pour gérer l’accès concurrent à la mémoire partagée, ainsi que des mécanismes de notification pour signaler aux workers quand une nouvelle requête est disponible.
1. Structure de la Mémoire Partagée
Tampon de Requêtes : Une zone de mémoire partagée où le serveur écrit les requêtes. Chaque requête aura une taille fixe pour simplifier la gestion.
Index : Un index pour suivre la position de la dernière requête écrite et celle lue, afin de gérer le FIFO (First In First Out) des requêtes.
2. Utilisation de Sémaphores
Sémaphore de lecture/écriture : Utiliser deux sémaphores :
Un sémaphore pour contrôler l’accès en écriture, permettant au serveur d’écrire dans le tampon lorsque c’est sûr.
Un sémaphore pour contrôler l’accès en lecture, permettant aux workers de lire une requête lorsqu’elle est disponible.
3. Mécanisme de Notification
Signalisation : Une fois qu’une requête est écrite dans le tampon, le serveur peut envoyer un signal (par exemple, à l’aide de signaux ou d’une variable conditionnelle) à un worker inactif pour l’informer qu’il y a une nouvelle requête à traiter.
4. Processus de Traitement
Serveur :
Récupère les requêtes des clients et les écrit dans le tampon de requêtes.
Utilise le sémaphore d’écriture pour s’assurer qu’il n’écrit pas pendant qu’un worker lit.
Notifie un worker libre pour commencer à traiter la requête.
Workers :
Attend la notification du serveur pour lire la requête dans le tampon.
Utilise le sémaphore de lecture pour garantir un accès sûr au tampon.
Une fois la requête traitée, écrit la réponse dans le tampon et utilise une autre notification pour informer le serveur.
5. Équité et Efficacité
Équité : Pour garantir que tous les workers partagent la charge équitablement, le serveur peut utiliser une stratégie de round-robin pour notifier les workers, leur permettant de prendre des requêtes dans l’ordre où ils sont disponibles.
Efficacité : En utilisant des sémaphores et des notifications, aucun worker ne reste inactif en attendant des requêtes, réduisant ainsi le temps d’attente pour les requêtes et maximisant l’utilisation des workers.
Conclusion
Cette approche permet de gérer efficacement la communication et la synchronisation entre le serveur et les processus workers, garantissant que chaque requête est traitée par un unique worker, tout en maintenant un système équitable et performant sur un système multicœur moderne.