L‘ordonnancement du processus est à la base des systèmes d’exploitation multiprogrammés. En répartissant l’unité centrale entre les processus, le système d’exploitation peut rendre l’ordinateur plus productif. Dans ce chapitre, nous présentons des exercices corrigés sur les concepts de base de l’ordonnancement, l’idée d’allocation de ressources et discutons en détail de l’ordonnancement de l’unité centrale. FCFS, SJF, Round-Robin, Priorité et les autres algorithmes d’ordonnancement devraient être familiers à vous.
Exercice 1:
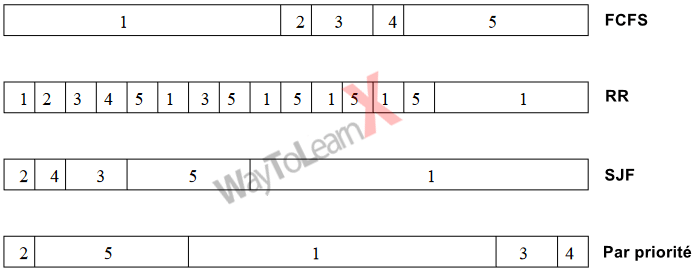
Considérons les processus suivants, la durée du temps d’utilisation du CPU (temps de rafale) étant exprimée en millisecondes:
On suppose que les processus sont arrivés dans l’ordre P1, P2, P3, P4, P5, tous au temps 0.
A. Dessinez quatre diagrammes de Gantt illustrant l’exécution de ces processus en utilisant l’ordonnancement FCFS, SJF, par priorité non préemptive (un numéro de priorité plus petit implique une priorité plus élevée), et RR – Round Robin (quantum = 1).
Les quatre diagrammes de Gantt sont:
B. Quel est le temps d’exécution (ou temps de rotation) de chaque processus pour chacun des algorithmes d’ordonnancement de la question A ?
Temps de rotation = Temps fin d’exécution – Temps d’arrivée
D. Lequel des ordonnancements de la question A permet d’obtenir le temps d’attente moyen le plus court (sur l’ensemble des processus) ?
SJF (hortest Job First).
Exercice 2:
Supposons que les processus suivants arrivent pour être exécutés aux moments indiqués. Chaque processus s’exécutera pendant la durée indiquée. Pour répondre aux questions, utilisez un ordonnancement non préemptif et basez toutes vos décisions sur les informations dont vous disposez.
+-----------------+-----------------+-----------------+
| ID du processus | Temps d'arrivée | Temps de rafale |
+-----------------+-----------------+-----------------+
| P1 | 0.0 | 8 |
+-----------------+-----------------+-----------------+
| P2 | 0.4 | 4 |
+-----------------+-----------------+-----------------+
| P3 | 1.0 | 1 |
+-----------------+-----------------+-----------------+
A. Quel est le délai d’exécution moyen (ou temps moyen de rotation) de ces processus avec l’algorithme d’ordonnancement FCFS ?
On sait que:
Temps de rotation = Temps fin d’exécution – Temps d’arrivée
Temps moyen de rotation = (Temps de rotation total) / (Nombre total de processus)
Temps moyen de rotation = 10.53 unités
B. Quel est le délai d’exécution moyen (ou temps moyen de rotation) de ces processus avec l’algorithme d’ordonnancement SJF ?
On sait que:
Temps de rotation = Temps fin d’exécution – Temps d’arrivée
Temps moyen de rotation = (Temps de rotation total) / (Nombre total de processus)
Temps moyen de rotation = 9.53 unités
C. L’algorithme SJF est censé améliorer les performances, mais remarquez que nous avons choisi d’exécuter le processus P1 au temps 0 parce que nous ne savions pas que deux processus plus courts arriveraient bientôt. Calculez le délai d’exécution moyen (ou temps moyen de rotation) si l’unité centrale est laissée inactive pendant la première unité, puis si l’ordonnancement SJF est utilisé. N’oubliez pas que les processus P1 et P2 sont en attente pendant cette période d’inactivité, et que leur temps d’attente peut donc augmenter.
Temps moyen de rotation = 6.86 unités
Exercice 3:
Considérons l’algorithme d’ordonnancement par priorité préemptive suivant, basé sur des priorités changeant dynamiquement. Les numéros de priorité les plus grands impliquent une priorité plus élevée. Lorsqu’un processus est en attente de l’unité centrale (dans la file d’attente des processus prêts mais non en cours d’exécution), sa priorité change à un taux α ; lorsqu’il est en cours d’exécution, sa priorité change à un taux β. Tous les processus reçoivent une priorité de 0 lorsqu’ils entrent dans la file d’attente. Les paramètres α et β peuvent être définis de manière à obtenir de nombreux algorithmes d’ordonnancement différents.
A. Quel est l’algorithme qui résulte de β > α > 0 ?
B. Quel est l’algorithme qui résulte de α < β < 0 ?
A. Quand β > α > 0
Dans ce cas, la priorité d’un processus en cours d’exécution augmente plus rapidement (β) que celle d’un processus en attente (α). Étant donné que les processus en cours d’exécution gagnent de la priorité plus rapidement, ils tendent à préempter les processus en attente qui n’ont pas été exécutés. Par conséquent, cette configuration favorise les processus qui utilisent activement le CPU, leur permettant de continuer à s’exécuter sans être interrompus tant qu’ils sont en cours d’exécution. Cela conduit à un comportement similaire à l’Ordonnancement Premier Arrivé, Premier Servi (First-Come, First-Served – FCFS), car une fois qu’un processus commence à s’exécuter, il est moins susceptible d’être préempté par d’autres en attente dans la file d’attente.
B. Quand α < β < 0
Dans ce scénario, les deux taux sont négatifs, ce qui signifie qu’au fil du temps, les priorités des processus en attente et en cours d’exécution diminuent. Cependant, comme β (le taux pour les processus en cours d’exécution) est moins négatif que α (le taux pour les processus en attente), les processus en cours d’exécution perdent de la priorité plus lentement que ceux en attente. En conséquence, les processus en cours d’exécution sont susceptibles de conserver leur priorité plus élevée pendant un certain temps, tandis que les processus en attente diminueront leur priorité plus rapidement. Ce comportement ressemble à un ordonnancement Dernier Entré, Premier Sorti (Last-In, First-Out – LIFO), car les processus les plus récents en attente seront priorisés par rapport aux processus plus anciens, ce qui conduit à une situation où les processus ajoutés le plus récemment sont plus susceptibles d’être programmés ensuite.
Résumé
A. β > α > 0 → FCFS
B. α < β < 0 → LIFO
Exercice 4:
Supposons qu’un algorithme d’ordonnancement (au niveau de l’ordonnancement CPU à court terme) favorise les processus qui ont utilisé le moins de temps processeur récemment. Pourquoi cet algorithme favorise-t-il les programmes liés aux E/S tout en ne laissant pas les programmes liés aux CPU dans un état de starvation permanent ?
L’algorithme d’ordonnancement qui favorise les processus ayant utilisé le moins de temps processeur récemment va privilégier les programmes liés aux E/S pour plusieurs raisons, tout en évitant de rendre les programmes liés aux CPU définitivement affamés.
Favoriser les programmes liés aux E/S
Courtes périodes d’utilisation du CPU: Les programmes liés aux E/S nécessitent généralement moins de temps CPU et passent plus de temps en attente d’opérations d’entrée/sortie. Ils ont donc des périodes d’utilisation du CPU relativement courtes, ce qui les rend plus susceptibles d’avoir moins de temps CPU accumulé.
Utilisation récente du CPU: L’algorithme favorise les processus ayant utilisé le moins de temps CPU récemment. Comme les programmes liés aux E/S utilisent le CPU pendant des périodes plus courtes, ils auront souvent une priorité plus élevée dans la file d’attente des processus.
Prévention de la starvation des programmes liés aux CPU
Changement de contexte fréquent: Les programmes liés aux E/S libèrent régulièrement le CPU pour effectuer leurs opérations d’E/S. Cela crée des occasions pour le planificateur d’allouer du temps CPU aux processus liés aux CPU.
Mécanismes d’équité: La plupart des algorithmes d’ordonnancement modernes intègrent des mécanismes pour garantir que tous les processus, y compris ceux liés aux CPU, reçoivent du temps CPU. Même s’ils consomment plus de temps CPU, ils ne seront pas définitivement affamés, car les programmes liés aux E/S cèdent souvent le CPU.
Conclusion
En résumé, cet algorithme d’ordonnancement favorise les programmes liés aux E/S en raison de leur utilisation courte du CPU tout en s’assurant que les programmes liés aux CPU continuent de recevoir du temps CPU périodiquement, évitant ainsi la starvation.
Exercice 5:
Expliquez les différences dans le degré de discrimination des algorithmes d’ordonnancement suivants en faveur des processus courts :
A. FCFS
B. RR
C. Queues multiples à rétroaction (Multilevel Feedback Queues)
Voici une explication des différences dans le degré de discrimination des algorithmes d’ordonnancement en faveur des processus courts:
A. FCFS (First-Come, First-Served)
Discrimination: FCFS désavantage les jobs courts.
Raison: Les jobs courts qui arrivent après des jobs longs doivent attendre que ces derniers soient terminés, ce qui entraîne des temps d’attente plus longs pour les jobs courts.
B. RR (Round Robin)
Discrimination: RR traite tous les jobs de manière égale.
Raison: Chaque travail reçoit des tranches de temps CPU égales. Cependant, les jobs courts peuvent quitter le système plus rapidement, car ils sont susceptibles de terminer leur exécution pendant leur première ou deuxième tranche de temps, surtout s’ils arrivent tôt dans le cycle.
C. Multilevel Feedback Queues
Discrimination: Les files d’attente à rétroaction multiple favorisent également les jobs courts.
Raison: Cet algorithme fonctionne de manière similaire à RR, mais il utilise plusieurs niveaux de priorité. Les jobs qui utilisent moins de temps CPU peuvent être déplacés vers des niveaux de priorité plus élevés, leur permettant d’obtenir plus de temps CPU et de terminer plus rapidement.
Résumé:
FCFS: Désavantage les jobs courts.
RR: Traite tous les jobs également, mais permet aux jobs courts de partir plus rapidement.
Multilevel Feedback Queues: Favorise activement les jobs courts en leur donnant une meilleure priorité.
Exercice 6:
Les questions suivantes se réfèrent à l’ordonnanceur Round Robin basé sur Java.
A. S’il y a actuellement un thread T1 dans la file d’attente de l’ordonnanceur avec une priorité de 4 et un autre thread T2 avec une priorité de 2, est-il possible pour le thread T2 de s’exécuter pendant le quantum de temps de T1 ? Expliquez.
B. Expliquez ce qui se passe si la méthode stop() du thread en cours d’exécution est invoquée pendant son quantum de temps.
C. Expliquez ce qui se passe si l’ordonnanceur sélectionne un thread à exécuter dont la méthode suspend() a été invoquée.
A. Est-il possible que le thread T2 s’exécute pendant le quantum de temps de T1 ? Expliquez.
Oui, si le thread T1 se bloque pour une raison quelconque (comme une opération d’E/S), la JVM programmera un autre thread. Dans ce cas, ce serait le thread T2.
B. Que se passe-t-il si le thread actuellement en cours d’exécution a sa méthode stop() invoquée pendant son quantum de temps ?
Le reste de son quantum de temps sera partagé par tous les autres threads dans la file d’attente en utilisant l’algorithme d’ordonnancement par défaut de la JVM.
C. Que se passe-t-il si le planificateur sélectionne un thread à exécuter qui a eu sa méthode suspend() invoquée ?
Le reste de son quantum de temps sera également partagé par tous les autres threads dans la file d’attente en utilisant l’algorithme d’ordonnancement par défaut de la JVM.
Exercice 7:
Le planificateur UNIX traditionnel impose une relation inverse entre les numéros de priorité et les priorités : plus le numéro est élevé, plus la priorité est faible. Le planificateur recalcule les priorités des processus une fois par seconde en utilisant la fonction suivante :
Priorité = (utilisation récente du CPU / 2) + base
où base = 60 et l’utilisation récente du CPU fait référence à une valeur indiquant à quelle fréquence un processus a utilisé le CPU depuis que les priorités ont été recalculées. Supposons que l’utilisation récente du CPU pour le processus P1 est de 40, pour le processus P2 est de 18, et pour le processus P3 est de 10.
A. Quelles seront les nouvelles priorités pour ces trois processus lorsque les priorités seront recalculées ?
B. Sur la base de ces informations, le planificateur UNIX traditionnel augmente-t-il ou abaisse-t-il la priorité relative d’un processus liés aux CPU ?
Réponse:
A. Les priorités assignées aux processus sont respectivement 80, 69 et 65.
B. Le planificateur abaisse la priorité relative des processus liés aux CPU.
Explication:
Calcul des Priorités:
Interprétation des Résultats:
Les valeurs des priorités calculées (80, 69, 65) signifient que P1 a la priorité la plus faible (80) et P3 la plus élevée (65).
Dans le contexte du planificateur UNIX, un numéro de priorité plus élevé indique une priorité plus faible. Ainsi, P1, qui est probablement un processus liés aux CPU avec une utilisation élevée, a une priorité plus basse.
Conclusion:
Le planificateur UNIX traditionnel abaisse donc la priorité relative des processus liés aux CPU, car une utilisation intensive du CPU (comme pour P1) conduit à une augmentation du numéro de priorité (donc une diminution de la priorité). Cela encourage le système à donner plus de temps à des processus moins gourmands en CPU.