
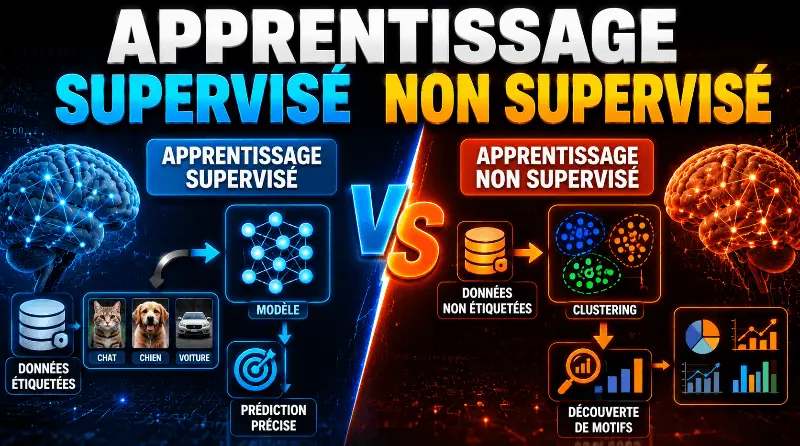
Différence entre apprentissage supervisé et non supervisé
Dans le domaine du machine learning, il existe deux principaux types de tâches: supervisées et non supervisées. La principale différence entre les deux types réside dans le fait que l’apprentissage supervisé se fait sur la base d’une vérité fondamentale. En d’autres termes, nous avons une connaissance préalable de ce que devraient être les valeurs de sortie de nos échantillons. Par conséquent, l’objectif de l’apprentissage supervisé est d’apprendre une fonction qui, à partir d’un échantillon de données et des résultats souhaités, se rapproche le mieux de la relation entre entrée et sortie observable dans les données. En revanche, l’apprentissage non supervisé n’a pas de résultats étiquetés. Son objectif est donc de déduire la structure naturelle présente dans un ensemble de points de données.

Table de comparaison
| Apprentissage supervisé | Apprentissage non supervisé | |
|---|---|---|
| Données d’entrée | Utilise les données connues et étiquetées comme entrées | Données inconnues en entrée |
| Complexité informatique | Très complexe | Moins de complexité informatique |
| Temps réél | Utilise l’analyse hors ligne | Utilise l’analyse en temps réel des données |
| Sous-domaines | Classification et régression | Exploitation de règles de clustering et d’association |
| Précision | Produit des résultats précis | Génère des résultats modérés |
| Nombre de classes | Nombre de classes connues | Le nombre de classes n’est pas connu |
Apprentissage supervisé
La majorité des experts machine learning utilisent un apprentissage supervisé.
L’apprentissage supervisé consiste en des variables d’entrée (x) et une variable de sortie (Y). Vous utilisez un algorithme pour apprendre la fonction de mappage de l’entrée à la sortie.
Y = f (X)
Le but est d’appréhender si bien la fonction de mappage que lorsque vous avez de nouvelles données d’entrée (x), vous pouvez prévoir les variables de sortie (Y) pour ces données.
C’est ce qu’on appelle l’apprentissage supervisé, car le processus d’un algorithme tiré de l’ensemble de données, et peut être considéré comme un enseignant supervisant le processus d’apprentissage. Nous connaissons les réponses correctes, l’algorithme effectue des prédictions itératives sur les données d’apprentissage et est corrigé par l’enseignant. L’apprentissage s’arrête lorsque l’algorithme atteint un niveau de performance acceptable.
Les problèmes d’apprentissage supervisé peuvent être regroupés en problèmes de régression et de classification.
- Classification: Un problème de classification survient lorsque la variable de sortie est une catégorie, telle que «rouge» ou «bleu».
- Régression: Un problème de régression se pose lorsque la variable de sortie est une valeur réelle, telle que «dollars» ou «poids».
Certains types de problèmes fondés sur la classification et la régression incluent la prévision et la prévision de séries chronologiques.
Voici quelques exemples populaires des algorithmes d’apprentissage supervisé:
- Régression linéaire pour les problèmes de régression.
- Forêt aléatoire pour les problèmes de classification et de régression.
- Soutenir les machines à vecteurs pour les problèmes de classification.

Apprentissage non supervisé
L’apprentissage non supervisé consiste à ne disposer que des données d’entrée (X) et pas de variables de sortie correspondantes.
L’objectif de l’apprentissage non supervisé est de modéliser la structure ou la distribution sous-jacente dans les données afin d’en apprendre davantage sur les données.
Celles-ci sont appelées apprentissage non supervisé car, contrairement à l’apprentissage supervisé ci-dessus, il n’y a pas de réponse correcte ni d’enseignant. Les algorithmes sont laissés à leurs propres mécanismes pour découvrir et présenter la structure intéressante des données.
Les problèmes d’apprentissage non supervisés peuvent être regroupés en problèmes de clustering et d’association.
- Mise en cluster: Un problème de mise en cluster est l’endroit où vous souhaitez découvrir les regroupements inhérents dans les données, tels que le regroupement des clients en fonction du comportement d’achat.
- Association: Un problème d’apprentissage de règle d’association est l’endroit où vous souhaitez découvrir des règles décrivant une grande partie de vos données, telles que les acheteurs de X ont également tendance à acheter Y.
Voici quelques exemples populaires des algorithmes d’apprentissage non supervisés:
- k-moyen pour les problèmes de clustering.
- Algorithme A-priori pour les problèmes d’apprentissage des règles d’association.
Conclusion
L’apprentissage supervisé est la technique permettant d’accomplir une tâche en fournissant aux systèmes une formation, des modèles d’entrée et de sortie, tandis que l’apprentissage non supervisé est une technique d’auto-apprentissage dans laquelle le système doit découvrir les caractéristiques de la population d’entrée par lui-même.



